One of the common issues people encounter with an LLM (like ChatGPT, Anthropic Claude, Meta Llama, Google Gemini etc) is that they are not getting the answers they expect from the LLM.
What can you do in this case? Below I’ll explain why this happens and how you can try to solve it.
What affects the answers by an LLM
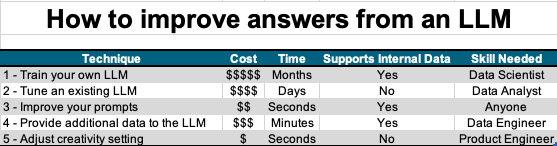
There are five primary ways you can affect the answers from an LLM:
- Train your own LLM
- Tune an existing LLM
- Improve your prompts
- Provide additional data to the LLM
- Adjust creativity vs accuracy setting
Let’s talk about these one by one and provide advice on when you should use each method.
Train your own LLM

Training your own LLM (Large Language Model) means you start with an LLM with no learning i.e., a model with no weights defined (don’t know what “weights” are? Conceptual Understanding of Deep Learning.) Then you show it a lot of examples so it can iteratively calculate the weights. For each example, the training process updates the existing weights in the model so the model would predict a value close to the actual value in a example.
In previous article we explained how deep learning works and how deep learning models train: Conceptual Understanding of Deep Learning. The key thing to understand here is that training large models requires a lot of examples and a lot of processing power to adjust the model weights for each example.
A rule of thumb is that you need 10x as many examples for training as the number of parameters in a simple deep learning model (so a 1,000 parameter model needs about 10,000 examples to train.). The more parameters that a model has the smarter that model will tend to be.
LLMs are very complex deep learning models so the rule of thumb is that you need 100x as many sentences to train as the number of parameters in an LLM. As an example GPT 3.5, an older LLM, has 175 billion parameters and newer LLMs have much more. So you can imagine how many sentences are needed to train a model with this many parameters. It is estimated that GPT4 required 250 billion sentences to train at a cost of $100M!
You can think of training an LLM to an analogy of taking a four year old and trying to teach them to be a doctor. It will take a lot of time and a lot of education for that four year old kid to learn as much as a doctor. The training process would look like showing the kid a fact in medicine and the kid would update his knowledge so he would predict that same fact. For more information on how training a model works you can read Deep Learning for the Average Person.
Training your LLM is necessary if you are not working with a natural language like English where LLMs already exist. For example, when training a model to predict protein sequences you are not dealing with a natural language like English so using an existing LLM like ChatGPT is not possible.
However training your own LLM is an overkill in most cases. As mentioned above, training an LLM takes 100x as many training examples as the number of parameters so it will take a long time and cost a lot in computer processing power.
OpenAI GPT4 was estimated to have cost $100M to train. GPT5 is expected to cost $1B to train.
Advice: Don’t train your own LLMs if you are working in English or a language supported by the commercial LLMs.
Tune an existing LLM

Tuning your LLM involves showing an already trained LLM some examples of what correct answers look like for certain questions.
One analogy to understand this is let’s say you’re playing the game to estimate how many M&Ms are in a jar.

Your initial answer will be wrong. But let’s say we show you answers from a reasonably large number of other people. You would be able to then estimate the number of M&Ms better.
This is essentially how tuning an LLM works. You provide the LLM a number of questions and answers (typically from humans but could be from any source). The LLM then updates its weights so its answers are closer to answers you provided. Then when you ask the LLM questions similar to the ones that you’ve provided its answers will be closer to the sample answers you provided.
In a real example, let’s say you asked the LLM which car is the fastest. The LLM gave the answer “Ford”. Then you provide it a number of answers to this question such that 80% of the people said Ferrari, 15% said Lamborghini and 5% said Ford. The LLM can now tune itself so when you ask it the same question again it will answer “Ferrari” this time.
Technically this is a form of “Transfer Learning”. In Transfer Learning, you take an existing model and provide it additional data to slightly adjust the weights.
Fine tuning is great when you’re trying to adjust the answers by an LLM and you have a set of questions and answers from another source such as humans or other models.
Fine tuning is a much cheaper and much faster operation than training a model from scratch. A rule of thumb is that it takes you about the same number of supplied answers as the number of parameters in the model although in most cases a small number of samples like 500 can effectively tune a 175 billion parameter model for a small set of questions.
However the two other options mentioned below are even cheaper and even faster than fine tuning.
Advice: Use fine tuning when the two other mechanisms below don’t give you the results you want.
Improve your prompts

A prompt is set of questions you ask the LLM in a conversation.
As described in All ChatGPT does is complete the sentence, the LLM takes the prompt and starts writing sentences one word at a time to continue the text in the prompt. Hence prompts are really important to set the context so the LLM can continue the text.
Think of prompts like the prompts students get in a test when writing an essay.

If students were given a prompt “Write an essay about a US president” then different students may write the essay about different presidents and they may write about different aspects of the presidency; one student may write about the life of the president before they were elected, another may write about how they were as a president and another may write about the president’s life after they left office.
Contrast that to a prompt in the test like “Write about how Bill Clinton’s policy on NAFTA affected the US economy in 2000”. Now you would expect the students to write essays that are more in line with what you wanted.
In LLMs, there are two types of prompts: system and user. System prompts are used to focus the role of the LLM in the current conversation e.g., “you are a math teacher” or “you are an English teacher” or “you are a 4th grade student”. User prompts are then used to ask this LLM to answer a question leveraging the role it was assigned in system prompts.
Currently prompt writing is currently a “secret art”. Very few people know how to do it well but there are many people online claiming to be able to help you.

Remember in the early days of Google Search, it was a secret art to know what to type in the Google Search box to get the results that you wanted. There were even companies that you could pay and tell them what you wanted and they would tell you what to type in the Google search box.
Nowadays we’ve all learned how to use Google Search AND Google Search has learned from our search queries to get smarter about how humans ask questions.

LLM prompting is in the same stage as Google Search was in its infancy. This is a short lived problem as we will all learn over the next years what types of prompts work for LLMs and the LLMs will learn how humans tend to prompt. Just like everyone knows how to use Google Search well now, eventually everyone will know how to prompt LLMs well.
In the meantime, the most important principle to remember is from the essay writing analogy above: define what you want in as much detail as possible and clear up any ambiguity in your question.
In prompting, you can also instruct the LLM to answer based on a smaller subset of information. If you ask it “which car is the fastest” you will get answers based on the whole internet. We know people on the internet don’t necessarily follow facts!

However if you ask the LLM “which car is fastest according to Car and Driver magazine and Consumer Reports” you will now get answers that rely on those two reliable sources instead of the whole internet.
Prompting is very cheap and fast compared to training and tuning. The cost to you will be based on the how long your prompts are since the LLMs charge by the number of words (actually tokens) in your prompts (and the number of tokens in the LLMs answer).
So you need to balance providing really detailed prompts with the cost to process the larger prompts. An effective technique here can be to use a smaller, cheaper LLM to summarize your prompts (reducing the length of the prompts) before passing them to the normal LLMs.
Advice: Prompting is the easiest and cheapest way to control the answers you’re getting. If you have non-technical people using your product, you can specify system prompts in your LLM so the LLM provides answers closer to what you want.
Provide additional data to the LLM

Sometimes the information needed to answer a question is not available on the public internet. For example, answering the question “How has my company’s revenue increased over the past three years” will be hard to do well if your company does not post its financial statements on the internet.

Another case is when the information on the internet is not trustworthy and so you want to provide the LLM your own trusted information.
To solve these issues, you can provide the LLM your own information to use in answering your question.
There are three main ways to provide your own information to an LLM:
- Provide the information in the prompt
- Provide the LLM a function to call to get information
- Provide the LLM a web service to call to get information
1 – Provide the information in the prompt
Providing the information in the prompt is the original method (referred to as RAG – Retrieval Augmented Generation).
In this method, you include your information in the prompt. For example, you may supply a prompt like “Our revenue for 2021 was $100M, for 2022 $200M and for 2023 $500M. How has my company’s revenue increased over the past three years”. The LLM can now use the extra information you provided in the prompt to answer the user’s question and will provide a more accurate answer than if you did not provide the revenue numbers in the prompt.
Advice: This is the simplest method. There are two drawbacks to this method.
Length of Prompts: First drawback is that there is a limit to how long the prompts can be and the LLM charges by the number of words (tokens) in the prompt. Also remember from How the transformer remembers that the LLM extracts just the essence from your prompt so longer prompts CAN confuse the LLM.
What to include: The other drawback is how to figure out which information to include in the prompt since the user may ask any question that may or may not be related to revenue. How can you determine whether to provide the revenue information in the prompt or some other information?
2 – Provide the LLM a function to call to get information
The second method is to provide the LLM a function (a piece of software code written in a language like Python or Javascript) it can call when the LLM needs some information. This is called Function Calling (used to be called Tools).
You register your function with the LLM and tell the LLM what the function does e.g., “this function gets the revenue of my company given the year”. If answering the user’s question requires this information THEN the LLM will call your function with the year that it wants the revenue for.
Your function can run any code to get this such as querying your database, calling a web service or doing a math calculation. Then your function can return the results to the LLM so it can answer the user’s question.
This method (function calling) is better when you are adding simpler data query abilities since you don’t need to create and manage another web service. This method also requires that you write your code in Python or Javascript. While you can potentially use other languages but the support in the LLM is not as good for other programming languages.
3 – Provide the LLM a web service to call to get information
The third method is to provide the LLM a web service that the LLM can call to get this information. This is called GPT Actions.
You can register a web service with the LLM and tell the LLM what the web service does. Your web service must be able to provide an OpenAPI schema so the LLM can discover how to call your web service with the right parameters and parse the result from your web service.
This method is better when your data querying is complex since you can separate the code into a web service that is easier to test and maintain.
Advice: If your data is small and you have a good idea what the users will ask then first method of providing information in the prompt is best. If your data is large or users are not limited in the questions they can ask then choose the second or third method.
If your data query logic is simple and you can write it in Python or Javascript then go with the second method. But if the data query logic is complex, in a language other than Python or Javascript or is managed by another team then go with the third method.
Adjust creativity vs. accuracy setting

As we learned in Many tasks are simpler than we thought, the LLMs simulate creativity by introducing a bit of randomness in their answers.
This randomness is great when writing an essay, a poem or a story because it makes these answers more creative and interesting. However this randomness is bad when you’re asking for a factual answer; the LLM may randomly give you a slightly less accurate answer.
The level of randomness is determined by a parameter called “temperature” in LLMs. If you set the temperature lower then you will get more accurate but less creative answers while if you set the temperature higher than you will get less accurate but more creative answers.
The ChatGPT UI does not provide a way to control this setting however when you incorporate LLMs into your own solutions using the OpenAI APIs you can set this temperature setting appropriately depending on your use cases.
Whenever someone complains about hallucinations in LLMs the first question I ask is whether they have set the temperature settings. Usually I get a blank stare. You can’t judge hallucinations in the LLM unless you set the temperature to zero first! Read more about Hallucinations in LLMs.
Advice: If your use cases require accurate or deterministic answers then set the temperature to 0. If your use cases require creative answers then set the temperature to 1.
Support in Other LLMs
Note that while above we referred to OpenAI LLMs such as GPT4, the same techniques work in all the major LLMs including Anthropic Claude, Google Gemini, Meta Llama and others.
Summary

When your LLM is not giving you good answers, here’s the workflow I recommend:
- Always prompt in as clear and unambiguous way as possible to get better answers. A vague prompt will likely result in an unexpected answer.
- Is the information required to answer the question not available or trustworthy on the internet? If yes, provide your correct information to the LLM either in the prompt, via a function or via a web service.
- If you want more accurate or more creative answers set the temperature setting of the LLM appropriately.
- If you can collect a set of questions and answers from humans (or other data sources) then fine tune the LLM model.
- If you are dealing with a different content than natural languages like English then train your own model. Leave the expensive model training to commercial LLM providers like OpenAI, Anthropic, Meta, Google or others.